
Graphs
[latexpage]
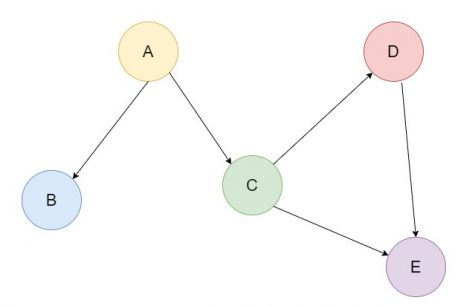
Graphs are a collection of nodes (also known as vertices), connected by edges (sometimes called arcs). A graph is called undirected if the edges connecting the nodes have no direction, whereas if the edges specify a direction between a source node and a destination node, the graph is called a directed graph (or a digraph). Edges can have weights or costs associated with them, and in this case the graph is called a weighted graph (in contrast, an unweighted graph is one whose edges have no weights/costs):
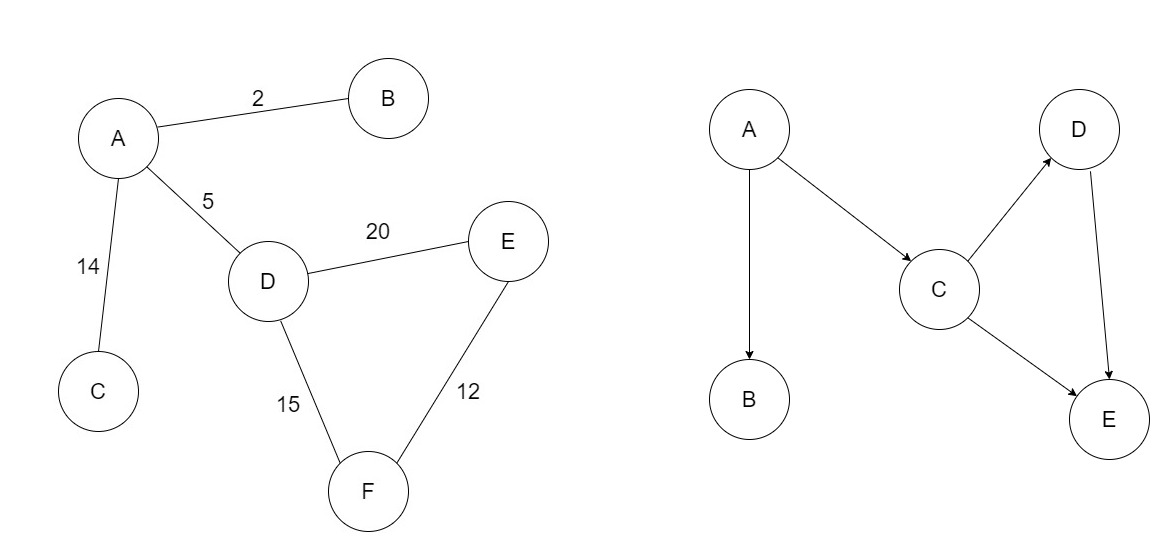
Left: a weighted, undirected graph. Right: an unweighted, directed graph
Properties of graphs
Just a quick summary of some of the most important properties of graphs that will help us choose an implementation based on time and space complexity of graph algorithms: let’s indicate with $|V|$ the total number of vertices/nodes of the graph and with $|E|$ the number of edges. The following limitations are true for directed and undirected graphs respectively:
$ 0 \leq |E| \leq |V|(|V| – 1) $ for directed graphs
$ 0 \leq |E| \leq \frac{|V|(|V| – 1)}{2 }$ for undirected graphs
A graph is said to be dense if the number of edges is close to the maximum number of edges, or sparse if it’s much less (these are not mathematically accurate definitions, nor there’s a clear separation between the two). This classification will be useful when we need to decide which data strucure to use to represent the graph in our code.
Graph data structure representation
I’ll now show you three implementations of a graph data structure: there are many ways in which we can store vertices and edges inside a graph, and each comes with its own trade-offs as far as performance and memory usage are concerned. The basic operation performed on a graph is traversal, which consists in visiting all the graph nodes sequentially. There are two kind of graph traversal algorithms: breadth-first and depth first. In order to perform both we need to determine all the vertices that are adjacent/connected by an edge to a given vertex, so this is the basic operation that I’ll analyze to see how well each implementation fares in term of speed and memory. Another useful operation is knowing if a given node is connected to another so I’ll consider that as well.
Edge list
The simplest way to represent a graph is to store two lists: an ordered list of vertices and a list of edges. A vertex is a simple struct containing whatever data we want to store into our graph (for example the name of the vertex itself). An edge stores two references that point into the vertex list (for example a couple of indices), each one representing a vertex in a connected pair, and a weight, if the graph is weighted:
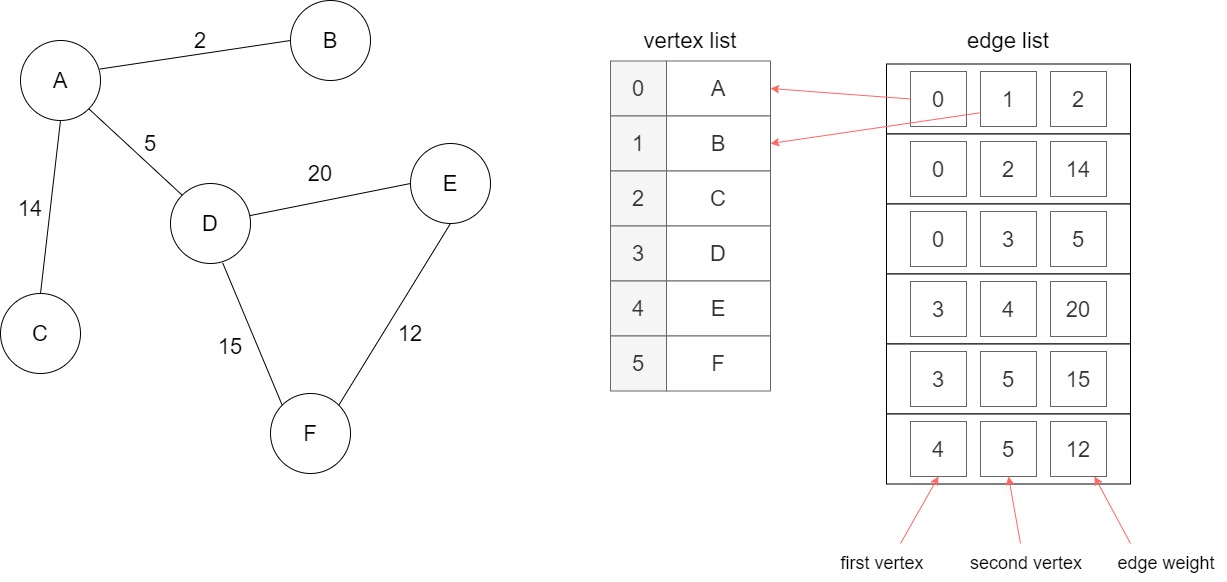
A graph with an edge list: each edge contains the indices of the connected vertices, and optionally the edge weight.
A node is added to the sequential list, so each vertex is identified by an index inside the list. Here, I use a vector, but a static array would do as well, if we know beforehand how many nodes are in the graph. Adding an edge is as simple as specifying the vertices (better, their indices inside the vertex list) that the edge connects. Optionally, we can specify a weight, if the graph is weighted. Again I use a vector for the edge list as well:
#include "../../vector/vector.hpp"
template <typename T>
class Graph
{
private:
struct Node
{
T data;
};
struct Edge
{
unsigned int nodeIndex1;
unsigned int nodeIndex2;
float weight;
};
public:
void AddNode(const T &data) { mNodes.InsertLast(Node{data}); }
void AddEdge(unsigned int nodeIndex1, unsigned int nodeIndex2, float weight = 1.0f) { mEdges.InsertLast(Edge{nodeIndex1, nodeIndex2, weight}); }
private:
Vector<Node> mNodes; // list of nodes
Vector<Edge> mEdges; // list of edges
};
We can also represent a directed graph with an edge list, if we assume that the pair of indices in an edge is not symmetric: an edge with the pair {0,1} is not the same as an edge with {1,0}, meaning that the connection is from 0 to 1 and not vice-versa (this will be important when we’ll search for all the adjacent vertices of a vertex).
In order to check whether a node is connected to another we must linearly traverse the entire edge list, which takes time proportional to $O(|E|)$. We saw that for a gaph $|E| \leq |V|(|V| -1)$ so we’re really performing the operation in $O(|V|^2)$ time, in the worst case.
Adjacency matrix
Another way to represent a graph is to store the connections between vertices in a matrix, called adjacency matrix, a square matrix where the i-th row corresponds to the i-th vertex in the vertex list, and the j-th element of the row is the weight of the edge between the i-th and the j-th vertex in the vertex list:
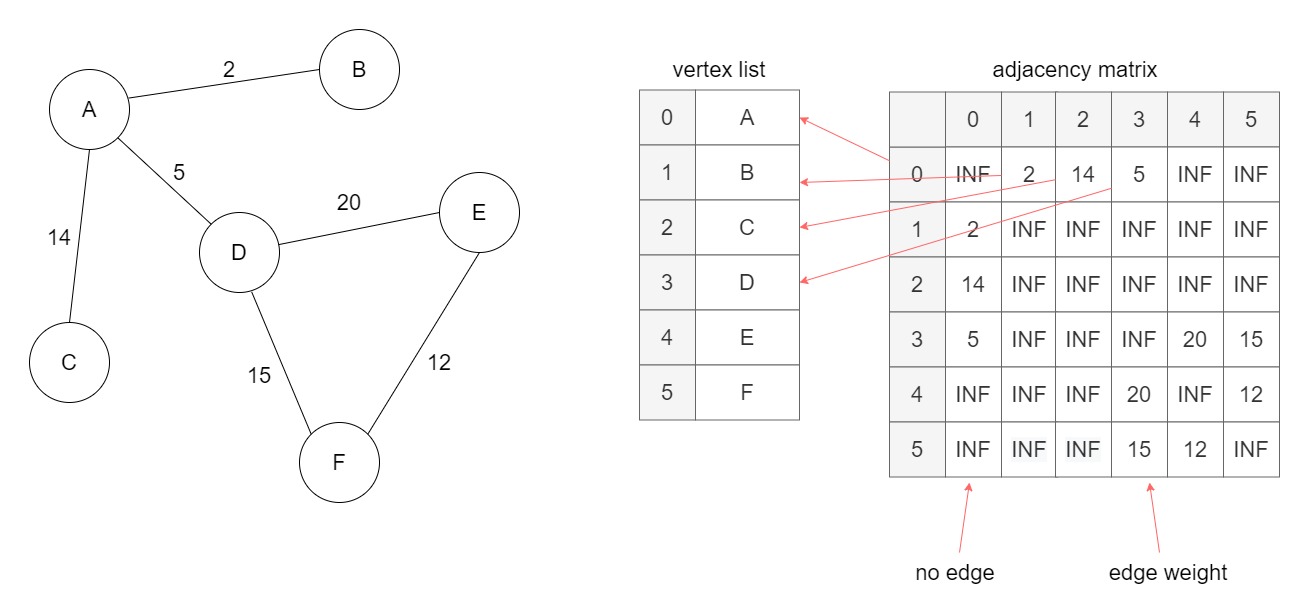
A graph implemented with an adjacency matrix: each element [i,j] of the matrix represent the weight of the edge between vertices i and j (INF means no connection).
#include "../../vector/vector.hpp"
#include <limits>
template <typename T>
class Graph
{
private:
struct Node
{
T data;
};
public:
void AddNode(const T data);
void AddEdge(unsigned int nodeIndex1, unsigned int nodeIndex2, float weight = 1.0f, bool directed = false);
private:
static const int INF = std::numeric_limits<int>::max();
Vector<Node> mNodes;
Vector<Vector<float>> mAdjacencyMatrix;
};
template <typename T>
template <typename U>
void Graph<T>::AddNode(U &&data)
{
mNodes.InsertLast(Node{data});
mAdjacencyMatrix.InsertLast(Vector<float>());
for (Vector<float> &vector : mAdjacencyMatrix)
vector.Resize(mAdjacencyMatrix.Size(), INF);
}
template <typename T>
void Graph<T>::AddEdge(unsigned int nodeIndex1, unsigned int nodeIndex2, float weight, bool directed)
{
mAdjacencyMatrix[nodeIndex1][nodeIndex2] = weight;
if (!directed) // adjacency matrix is symmetric for an undirected graph
mAdjacencyMatrix[nodeIndex2][nodeIndex1] = weight;
}
If the graph is undirected the adjacency matrix is symmetric, but if the graph is directed element $\{i,j\}$ is not the same as element $\{j,i\}$.
An adjacency matrix lets us find if a node is connected to another node in O(1) constant time, since it’s just a couple of array lookups. Finding all the connected nodes is just a matter of reading through a row of the matrix, and it is performed in O(|V|) linear time. An adjacency matrix representation requires a space complexity of $O(|V|^2)$ to store all the connections between vertices. Most of the graphs that are used in practice are sparse, meaning the adjacency matrix will have lots of INFs (or NILs, or whatevere value you choose for an absent edge) in it, and a lot of memory will be wasted storing those values.
Adjacency list
An adjacency list has one entry for each vertex, and each entry contains the list of all vertices (indices) to which that vertex is connected by an edge. The list elements are instance of an adjacency data srtuct, containing the index of the connected vertex and the edge weight:
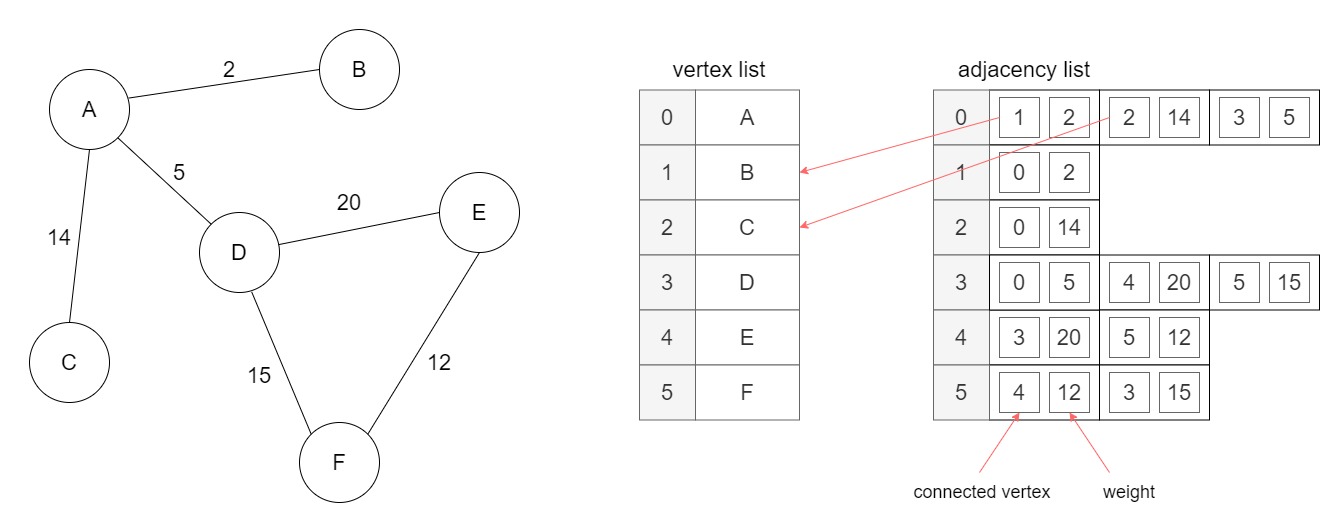
A graph represented with an adjacency list: each element in the list contains another list of edges for each vertex in the graph.
An adjacency list wastes less memory than an adjacency matrix, in the case of a sparse graph (the majority of real-world graphs are sparse), since it only has to store the adjacent vertices of a vertex. By walking the adjacency list for a vertex we can find if a vertex is connected to another in $O(|V|)$ in the worst case, but in practice if the graph is sparse it will take much less.
#include "../../vector/vector.hpp"
template <typename T>
class Graph
{
private:
struct Node
{
T data;
mutable bool visited = false;
};
struct AdjacencyData
{
unsigned int nodeIndex;
float weight;
};
public:
void AddNode(const T &data);
void AddEdge(unsigned int nodeIndex1, unsigned int nodeIndex2, float weight = 1.0f, bool directed = false);
private:
Vector<Node> mNodes;
Vector<Vector<AdjacencyData>> mAdjacencyList;
};
template <typename T>
void Graph<T>::AddNode(const T &data)
{
mNodes.InsertLast(Node{data});
mAdjacencyList.InsertLast(Vector<AdjacencyData>());
}
template <typename T>
void Graph<T>::AddEdge(unsigned int nodeIndex1, unsigned int nodeIndex2, float weight, bool directed)
{
mAdjacencyList[nodeIndex1].InsertLast(AdjacencyData{nodeIndex2, weight});
if (!directed) // adjacency matrix is symmetric for an undirected graph
mAdjacencyList[nodeIndex2].InsertLast(AdjacencyData{nodeIndex1, weight});
}
Graph traversal: depth-first search and breadth-first search
The graph traversal algorithms implementations are the same for all graph representations. They all use a function GetUnvisitedAdjacentNodeIndex() to find an adjacent node that hasn’t been visited by the traversal yet. It returns the index of the vertex if found, otherwise returns -1 (that’s why the function returns an int instead of an unsigned). To know if a node has been already traversed we store a boolean flag inside the node struct:
template <typename T>
class Graph
{
public:
struct Node
{
T data;
mutable bool visited = false; // data member used by traversal algorithms
};
int GetUnvisitedAdjacentNodeIndex(unsigned int nodeIndex) const; // changes between graph implementations
template <typename F>
void BreadthFirstSearch(unsigned int startNodeIndex, const F&f);
template <typename F>
void DepthFirstSearch(unsigned int startNodeIndex, const F&f);
template <typename F>
void DepthFirstSearchRecursive(unsigned int nodeIndex, const F&f);
// other members...
};
#include "../../ADT/queue/queue.hpp"
template <typename T>
template <class F>
void Graph<T>::BreadthFirstSearch(unsigned int startNodeIndex, const F &f) const
{
Queue<unsigned int> nodeQueue;
f(mNodes[startNodeIndex]); // visit node
mNodes[startNodeIndex].visited = true; // mark as visited
nodeQueue.Enqueue(startNodeIndex); // insert into queue
while (!nodeQueue.Empty())
{
unsigned int currentNodeIndex = nodeQueue.Front();
int unvisitedAdjacentNodeIndex;
while ((unvisitedAdjacentNodeIndex = GetUnvisitedAdjacentNodeIndex(currentNodeIndex)) != -1)
{
f(mNodes[unvisitedAdjacentNodeIndex]); // visit node
mNodes[unvisitedAdjacentNodeIndex].visited = true; // mark as visited
nodeQueue.Enqueue(static_cast<unsigned>(unvisitedAdjacentNodeIndex)); // insert into queue
}
nodeQueue.Dequeue();
}
for (const Node &node : mNodes) // reset visited flag
node.visited = false;
}
#include "../../ADT/stack/stack.hpp"
template <typename T>
template <class F>
void Graph<T>::DepthFirstSearch(unsigned int startNodeIndex, const F &f) const
{
Stack<unsigned int> nodeStack;
f(mNodes[startNodeIndex]); // visit node
mNodes[startNodeIndex].visited = true; // mark node as visited
nodeStack.Push(startNodeIndex); // push onto stack
while (!nodeStack.Empty())
{
unsigned int currentNodeIndex = nodeStack.Top();
int unvisitedAdjacentNodeIndex;
if ((unvisitedAdjacentNodeIndex = GetUnvisitedAdjacentNodeIndex(currentNodeIndex)) != -1)
{
f(mNodes[unvisitedAdjacentNodeIndex]); // visit node
mNodes[unvisitedAdjacentNodeIndex].visited = true; // mark node as visited
nodeStack.Push(static_cast<unsigned>(unvisitedAdjacentNodeIndex)); // push onto stack
}
else
nodeStack.Pop();
}
for (Node const &node : mNodes) // reset visited flag
node.visited = false;
}
template <typename T>
template <typename F>
void Graph<T>::DepthFirstSearchRecursive(unsigned int nodeIndex, const F&f)
{
static unsigned int level = 0U;
level++;
f(mNodes[nodeIndex]); // visit node
mNodes[nodeIndex].visited = true; // mark node as visited
int nextNode;
while ((nextNode = GetUnvisitedAdjacentNodeIndex(nodeIndex)) != -1)
DepthFirstSearchRecursive(nextNode, f); // push node onto (implicit) stack
level--;
if (level == 0U)
for (Node const &node : mNodes) // reset visited flag
node.visited = false;
}
Breadth-first search algorithm uses a FIFO queue as a helper structure to perform the traversal, Depth-first algorithm uses a pushdown stack instead, which can be explicit or implicit if recursion is used (I show both implementation in the code above). A function object is passed to the function to act as a visitor that implements the action to perform when visiting a node.
Both traversal algorithms need to find an adjacent vertex that hasn’t been already visited. The function GetUnvisitedAdjacentNodeIndex() takes a node as argument and returns the next unvisited adjacent node (or -1 if it finds none). In order to do so, it uses the list of vertices and whatever structure we use to represent edges/connections.
If we use an edge list, as we saw, we need to traverse the entire list in order to find all adjacent vertices to a given vertex:
template <typename T>
int Graph<T>::GetUnvisitedAdjacentNodeIndex(unsigned int nodeIndex) const
{
for (Edge edge : mEdges) // edge list
if (nodeIndex == edge.nodeIndex1 && !mNodes[edge.nodeIndex2].visited)
return edge.nodeIndex2;
else if (nodeIndex == edge.nodeIndex2 && !mNodes[edge.nodeIndex1].visited)
return edge.nodeIndex1;
return -1;
}
in this case we consider an undirected graph and we check both the first and the second vertex in the edge struct (if the graph was a digraph, we would consider only the first vertex, sice the edge goes from first to second). An adjacency matrix simplifies the search:
template <typename T>
int Graph<T>::GetUnvisitedAdjacentNodeIndex(unsigned int nodeIndex) const
{
for (unsigned int i = 0; i < mAdjacencyMatrix[nodeIndex].Size(); i++) // adjacency matrix
if (mAdjacencyMatrix[nodeIndex][i] != INF && !mNodes[i].visited)
return i;
return -1;
}
We take the row which corresponds to the vertex whose adjacent vertices we want to find, and scan the array of connections, remembering that an INF value stands for no edge betwee the two vertices. Using an adjacency list gives some advantages,as we saw earlier, in case of a sparse graph:
template <typename T>
int Graph<T>::GetUnvisitedAdjacentNodeIndex(unsigned int nodeIndex) const
{
for (AdjacencyData adjacency : mAdjacencyList[nodeIndex])
if (!mNodes[adjacency.nodeIndex].visited)
return adjacency.nodeIndex;
return -1;
}
In this example I used a vector to implement a list of edges, but we could use a linked list too. If we want to find out if a given vertex is adjacent to another, we could store the elements in the adjacency list as sorted by vertex index, and perform a binary search (it would be faster for retrieval, but insertions and removals would take more time): a bynary search tree would be a good choice to store the edges.